[자료구조] Ⅰ-5,6,7. 알고리즘 성능 분석, 복잡도
5. 알고리즘
● 알고리즘이란 문제를 풀기 위한 방식으로, 예시로는 10장의 카드가 무작위로 펼쳐져 있고 그 중 85를 찾기 위해 순서대로 찾기(Sequential Search - 순차탐색) , 반으로 나누어 중간과 먼저 비교하여 큰지 작은지를 통해 절반씩 탐색 범위를 줄여가며 찾기(Binary Search - 이진탐색), 가장 적은 수의 동전으로 거스름돈을 받기 위한 방법(그리디 알고리즘), 한붓 그리기 등이 있다.
● 알고리즘은 자료구조의 기본적 연산을 구현하기 위한 것으로, 같은 자료라고 해도 어떻게 저장, 표현되느냐에 따라 사용 가능한 알고리즘이 달라지며 알고리즘의 성능은 자료구조에 종속된다.
● 알고리즘의 표현 방식

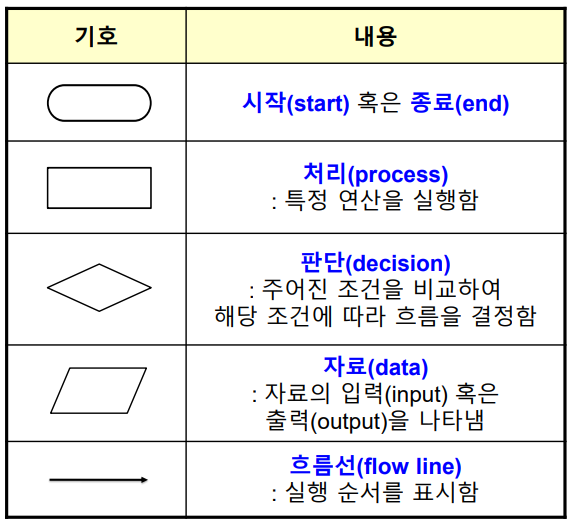
● 알고리즘의 조건
1) input: 외부에서 제공되는 자료 0개 이상
2) output: 적어도 1개 이상의 결과 생성
3) definiteness: 각 명령어는 의미가 명확해야 함
4) finiteness: 무한히 동작해서는 안됨
5) effectiveness: 불필요한, 오류 발생 연산(나누기 0과 같은) 을 포함해서는 안된다.
6. 알고리즘 성능 분석
● 프로그램 평가 기준: 성능 측정(machine dependent) , 성능 분석(machine independent)

(1) 공간 복잡도

1) Fixed Space Requirements(C) : 입출력의 특성과 무관하게 일정한 크기의 공간을 필요로 한다. 이는 프로그램의 실행에 필요한 기본적인 공간(instruction space(명령어 공간))으로 simple variable, fixed-size structured variable, constants 등을 위한 공간이다.
2) Variable Space Requirements(SP(I)): 입력의 특성에 따라 변하는 공간으로, 입출력의 수, 크기, 값들에 따라 달라진다. 예를 들어 recursive stack space(재귀함수에서 사용되는 스택 공간), formal parameters, local variables 등이 있다.
 |
 |
(2) 시간 복잡도

1) Compile Time(C): insance characteristics와 독립적으로, 컴파일 시 필요한 시간을 뜻하는데 이는 주로 알고리즘의 구조를 분석하고 코드를 변환하는데 필요한 시간을 나타낸다. 한번 컴파일이 되면 이후에 계속 실행됨.
2) Run(Execution) Time (Tp): 입력의 특성에 따라 달라지는 실행 시간으로, 알고리즘이 실행되는 동안 소요되는 시간을 뜻한다.
① System Clock을 이용하여 수행시간을 측정: 실제로 구현이 필요하다.

② 프로그램이 수행하는 연산의 횟수(명령문의 개수)를 계산: 직접 구현하지 않고서도 수행 시간을 분석할 수 있다.
● 시간 복잡도 함수 T(n)은 알고리즘이 수행하는 기본적 연산 횟수를 input size(n) 에 대한 함수로 표현하는 것으로, 연산 횟수를 계산하기 위해 프로그램을 여러 단계로 분할해야 한다. 이 때 프로그램 단계란, 의미있고 / 실행 시간이 인스턴스의 특성에 독립적인 프로그램 단위이다.


(3) 프로그램 단계 계산
: 두 가지로 나뉜다. 실행 명령문이 필요로 하는 프로그램 단계수만큼 count++ 하는거(variable count) / Tabular Method
1. Count 변수 이용
1) List of numbers를 Iterative Summing

2) List of numbers를 Recursive summing

3) Matrix addition

2. Tabular method

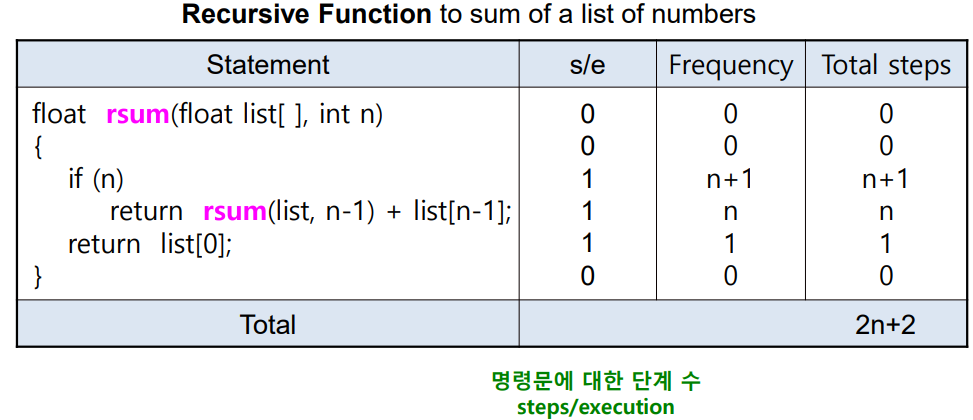


7. 알고리즘 복잡도 O(Big-Oh)
● 알고리즘의 시간복잡도는 보통 worst case analysis 에 따르는데, 입력에 따라 수행 시간이 다를 수 있기 때문.
- worst case analysis: 최악의 경우에도 이정도 성능 보장
- average case analysis: 입력의 확률 분포를 가정하여 분석 -> 입력이 무작위로 주어짐을 가정
- best case analysis: 주어진 문제의 lower bound와 같은 복잡도를 가진 알고리즘. 최적 알고리즘을 고안하기 위한 비교대상으로 활용됨
● Asymptotic Notation: 알고리즘 복잡도를 입력 크기에 대한 함수로 포함하고, 계수는 생략한 후 가장 큰 영향력을 주는 n에 대한 항만을 표시. 이는 n이 무한대로 커질 때 복잡도를 간단하게 표현하기 위한 방법

1. 빅-오 표기법: 복잡도의 점근적 상한을 의미. n이 증가함에 따라 이거 이상 클 수 없다
 |
 |
 |
 |

2. 빅-오메가 표기법: 복잡도의 점근적 하한을 의미. n이 증가함에 따라 이거보다 작을 수 없다.
 |
 |

3. 빅-세타 표기법: 빅오 표기와 빅오메가 표기가 같은 경우 사용.

 |
 |
4. 문제
 |
 |
5. 피보나치 수열 : n값이 커질수록 같은 항이 중복되어서 중복 호출이 증가 -> O(2^n)

6. 결론: 입력이 작으면 어떤 알고리즘을 사용하든 수행 시간은 비슷하지만, 입력이 커질 수록 차이는 크다 !